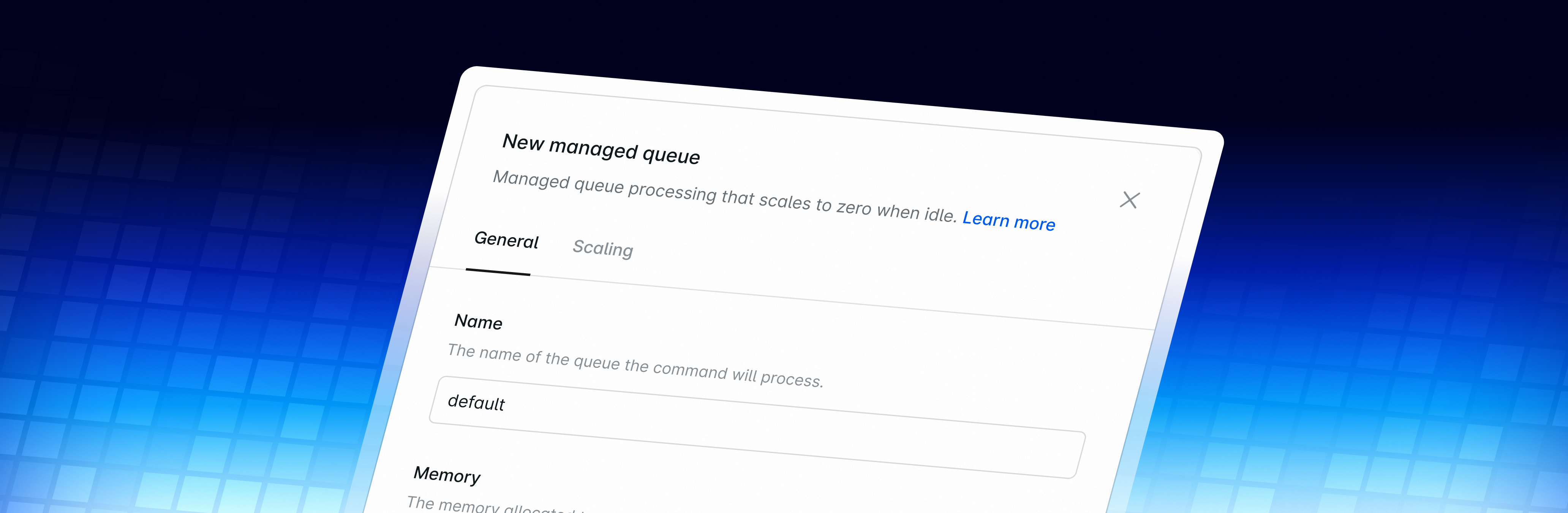
There are three things every user should get from their background job processing infrastructure. First, jobs should run reliably without constant attention. Second, when something fails, you should be able to see it immediately and resolve it without engineering escalation. And third, when your queues are empty, you should not be paying for idle compute.
Laravel Cloud's managed queues feature addresses all three. Now, every Laravel Cloud app can run queue workers in isolation from your app cluster, which scale based on the number of jobs waiting and drop to zero when there is nothing left to process, reducing costs.
What We Set Out to Solve
Customers running background jobs on Laravel Cloud kept running into the same set of problems, and this feedback shaped every decision we made while building managed queues.
Our previous attempt at solving long-running jobs, queue clusters, faced the following problems:
- Running queues at scale was unpredictable. Customers needed a more reliable foundation that could handle jobs that were not uniform in size.
- Queue depth couldn’t be measured independently. Cloud had to go through the application to read depth metrics. Low-traffic apps kept workers running even when queues were empty.
- Scaling added unused capacity. Multiple workers were packed into a single pod, scaling up within that pod until it hit capacity, then provisioning a new pod and repeating the cycle. Users were paying for capacity they had not yet used.
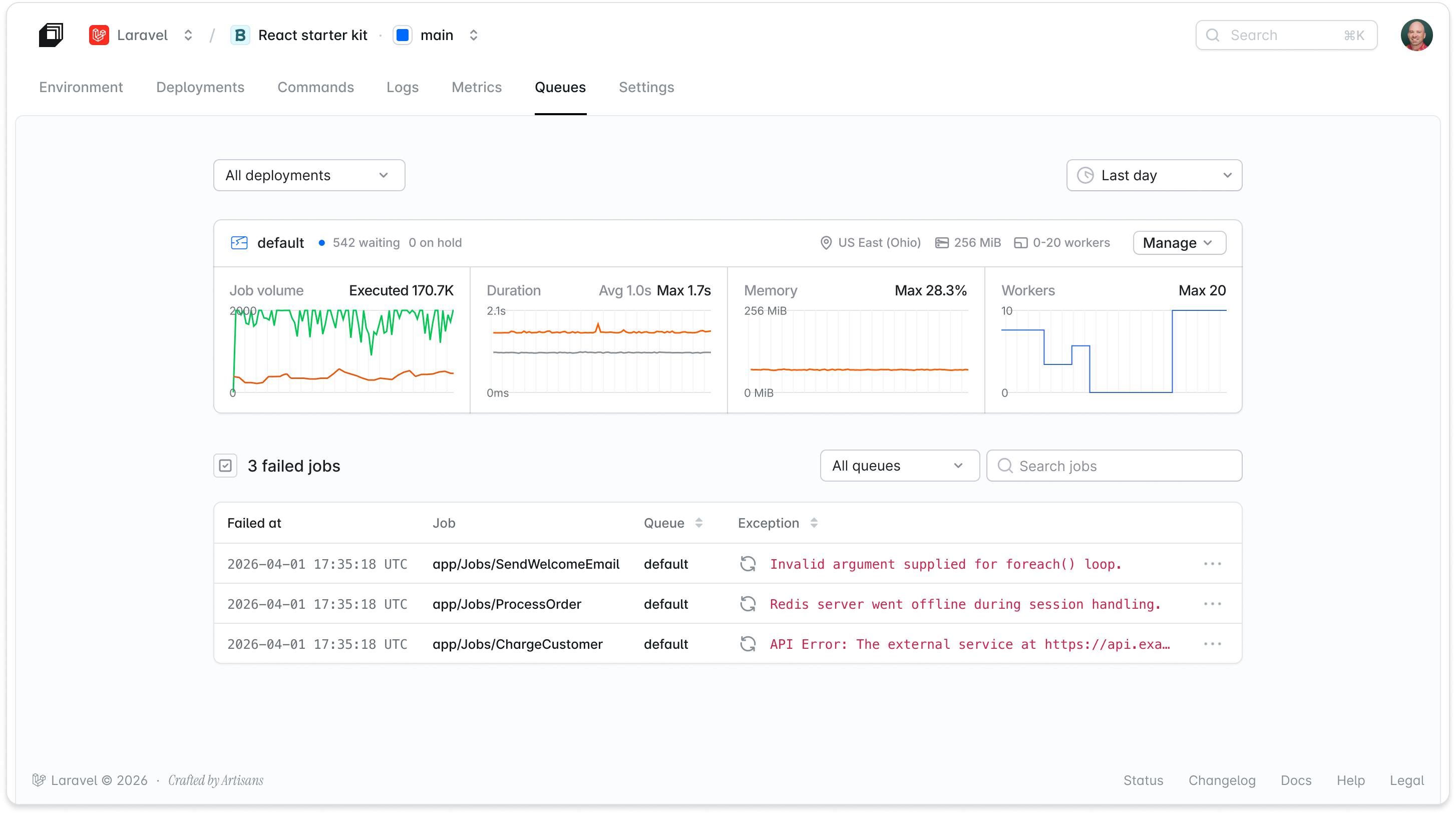
- Failed jobs were invisible. Customers could not visualize failed jobs, leaving them to dig through logs to find out what happened.
Managed Queues: A New Way to Run Background Jobs
Managed queues is a ground-up rebuild that solves each of these problems.
When queues are empty, workers scale to zero. When jobs arrive, workers scale back up based on how many are waiting and how long they have been there. You pay for the compute and queue operations that ran, not the capacity you reserved.
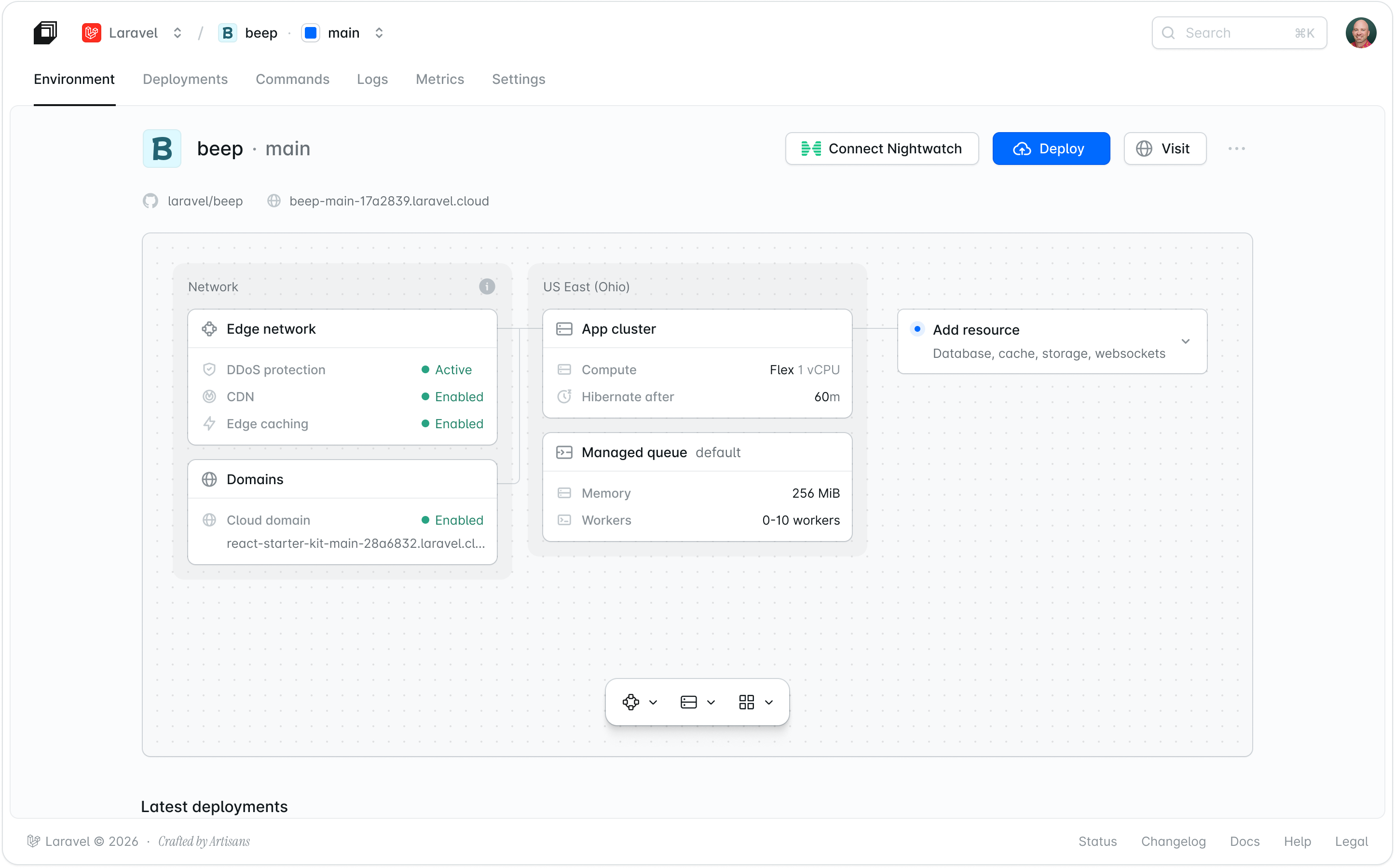
- Isolated workers: Workers run separately from the app cluster, so background jobs never compete with web traffic.
- Autoscaling based on queue pressure: Cloud scales workers up as jobs accumulate and back to zero when the queue clears.
- Per-queue configuration: Each queue is configured independently with its own compute size, max workers, and scaling configuration.
- Fine-tune scaling behavior: How often Cloud checks SQS for new jobs. A shorter interval means faster pickup; a longer interval reduces SQS API costs.
- Pause and purge: Pause halts processing without losing jobs. Purge clears the queue entirely.
- Queue dashboard: A real-time view of job volume, duration, average memory utilized, and replica counts. Failed jobs surface with full detail, and you can drill in to see why a job failed and retry it with one click.
For the first time on Laravel Cloud, teams can see exactly what failed, understand why, and recover without querying a database. A support team member fielding a complaint about a missing email or a failed export can investigate and retry directly from the dashboard.
How We Built It
Building managed queues meant rethinking the earlier assumptions we had made with the previous queue clusters solutions. Here’s what changed and why.
Owning the Queue
The most consequential decision was making Laravel Cloud the queue driver. With queue clusters, supporting any queue driver meant relying on the user's application to read depth metrics. "We needed to use their Laravel application to get metrics like depth," says Kieran Brown, Senior Software Engineer on the infrastructure team at Laravel.
Owning the queues removes that dependency entirely. Cloud reads depth straight from SQS, independent of whether the customer's application is healthy.
One Worker, One Pod
Queue clusters packed multiple workers into a single pod. When one worker ran out of memory, it caused the pod and everything running alongside it to crash.
Managed queues run every worker in its own isolated Kubernetes pod. A worker configured for 512 MB gets exactly that, guaranteed, with nothing else sharing the allocation. "Nothing's running together anymore," Kieran explains. "Every single managed queue worker runs in its own isolated pod, which means we can guarantee those resource allocations." One worker failing cannot affect another.
Horizontal scaling also changed the cost model. Before, scaling out meant provisioning an entirely new cluster to run one additional worker. With managed queues, each new worker is its own pod. This means that scaling adds 256 MB increments, not 4 GB ones.
Getting the Scaling Formula Right
The hardest part of building managed queues, and one we will keep refining, is the scaling algorithm itself. Queue depth alone is not enough of a signal. Five jobs in a queue sound manageable until each one takes two minutes to process. "If you only look at queue depth, you might get one worker spun up, but your queue would take forever," Kieran notes. "If each job takes 60 seconds to two minutes, even with just five messages, you're looking at ten minutes or more to clear."
The current implementation weighs multiple factors, including queue pressure and message age, and the formula will improve as real production data comes in.
Cold Starts and What Comes Next
Spinning up a new Kubernetes pod takes time, sometimes 10 seconds or more. For workloads with sustained throughput, that latency is negligible; workers are always already running when a job arrives, so there's nothing to spin up. But for low-volume queues that are likely to scale to zero, this latency becomes apparent.
“We are exploring preemptive scaling in collaboration with the Laravel Nightwatch team,” says Kieran. The idea is that Nightwatch can detect a dispatched job before it reaches SQS and signal the autoscaler to begin spinning up a worker in advance, so it is ready by the time the message lands. This is an area we will continue to improve as managed queues mature in production.
Who It Is For
Managed queues are designed to scale from the smallest hobby app to enterprise workloads, because the underlying model is the same at both ends: you pay for what runs and nothing more.
Hobby and side projects: Workers scale to zero alongside the rest of your app. Park a project for a few days, and you are not paying for idle worker compute while it sits untouched.
Applications with variable or burst load: If your application needs high worker concurrency for a fraction of the month, you pay for those hours, not for continuous capacity provisioned to handle peak load. Worker clusters require you to think carefully about sizing and run continuously at that size. Managed queues adjust automatically and bill accordingly.
Teams with multiple job types: Each Laravel queue name gets its own managed queue with independent configuration. A small compute allocation handles transactional email. A larger one handles video processing or report generation. Each scales independently and costs nothing when inactive.
Enterprise applications at scale: Early access customers are already running managed queues with more than 1,000 max replicas. At that scale, managed queues isn't just about cost, it's about offloading the operational work of running queue infrastructure entirely. Right-sizing workers, debugging failures across millions of jobs, and keeping throughput healthy is real engineering time that Cloud now handles for you.
Choosing Between Managed Queues and Worker Clusters
App cluster background processes are still supported. However, app cluster background workers run on the same compute as web traffic, so they are not a good option for workloads that need isolation or sustained throughput.
Managed queues are the recommended default for any queue workload, from low-volume hobby apps to high-throughput production systems.
One recommendation from the team: start with a single managed queue. Adding multiple queues can lead to idle workers on one queue while workers spin up on another. A second queue makes sense when different job types genuinely need different compute sizes.
Worker clusters are the right fit for sustained, predictable throughput, where a fixed number of workers running continuously and separately from the app cluster makes more sense than dynamic scaling.
Managed Queues Pricing
Managed queues is billed per second plus per million queue operations.
| Tier | Starter | Growth | Business |
|---|---|---|---|
| Max workers per queue | 3 | 25 | Unlimited |
| Queues per environment | 1 | 10 | Unlimited |
Get Started
Managed queues are now available on Laravel Cloud. Open your Laravel Cloud dashboard and select your application to create your first managed queue. If you’re not a Cloud user yet, you can start with $5 in free usage credits.
Full configuration details are in the managed queues documentation.