Picking the right AI model for Laravel development is harder than it looks.
So, for the past few weeks, we have been running an internal experiment called Boost Benchmarks. We had two goals:
- Find out which AI models handle real Laravel tasks best.
- Measure whether Laravel Boost, the MCP server that provides AI coding context for Laravel applications, actually improves agent performance (short answer: it does).
Boost Benchmarks is an evaluation framework that runs AI coding agents against real Laravel problems, verifies their output using Pest tests, and records everything that happens during the run. That includes the test results, token usage, tool calls, execution time, and total cost.
We tested six models: haiku 4.5, sonnet 4.6, and opus 4.6 by Anthropic; kimi k2.5 by Moonshot AI; and gpt-5.3 codex and gpt-5.4 by OpenAI.
We plan to open source the framework soon, but for now, this is a short walkthrough of how the system works. If you have questions or want to discuss the experiment, feel free to reach out to me at @pushpak1300.
Why Boost Benchmarks
Before this framework existed, improving Laravel Boost was mostly guesswork. Whenever we added a new tool, updated a guideline, or removed a feature, we could not confidently say whether the change actually helped agents perform better across different models.
That is what led us to build the benchmark framework. Now the process is much clearer. We run the evaluations, make a change to Boost, rerun the evaluations, and then compare the results. This loop allows us to measure the real impact of each change instead of relying on assumptions.
Along the way, the data also answered a broader question: which AI model is actually best for Laravel development?
How We Measured AI Model Performance on Laravel
AI coding agents have become impressively capable and very fast, but can we actually test how well they work? Each of our evaluations checks two things:
- Functionality: Does the implementation work? This is verified by real HTTP requests and test assertions against the running app.
- Architecture: Does the code follow Laravel conventions? This means no debug artifacts, correct class inheritance, and no obvious production mistakes.
How Evaluation Works
Each evaluation lives under evals/ and contains three parts:
The agent starts from a barebones Laravel app with no prebuilt solution. It has to inspect the project, implement the feature, and leave code that passes every test in the suite.
The 17 Evaluations
The benchmark suite covers a range of real-world Laravel work, from standard routing to specialized framework APIs.
| # | Task | Complexity |
|---|---|---|
| 001 | Add web + API routes with Blade views | Low |
| 002 | Dispatch a queue job | Low |
| 003 | RESTful Post CRUD API with validation | Medium |
| 004 | Interactive Artisan command | Medium |
| 005 | Cache layer implementation | Medium |
| 006 | Eloquent relationships (BelongsTo, HasMany, etc.) | Medium |
| 007 | Events and listeners | Medium |
| 008 | Notification system | Medium |
| 009 | Inertia.js shared data setup | Medium |
| 010 | File uploads with storage | Medium |
| 011 | Livewire counter + contact form components | High |
| 012 | Laravel Folio page routing | Medium |
| 013 | Feature flags with Laravel Pennant | High |
| 014 | Inertia.js form with validation | High |
| 015 | MCP server with custom tools | High |
| 016 | Laravel AI SDK agent loop | High |
| 017 | Socialite GitHub OAuth login | High |
Running an Evaluation
A typical run looks like this:
For each model, the runner copies the input/ directory into a temporary workspace, runs the agent via OpenCode with the prompt and model configuration, then merges the suite/ directory and runs Pest. Results are written to results/<eval_name>/ as JSON. Multiple evaluations run concurrently.
The Results
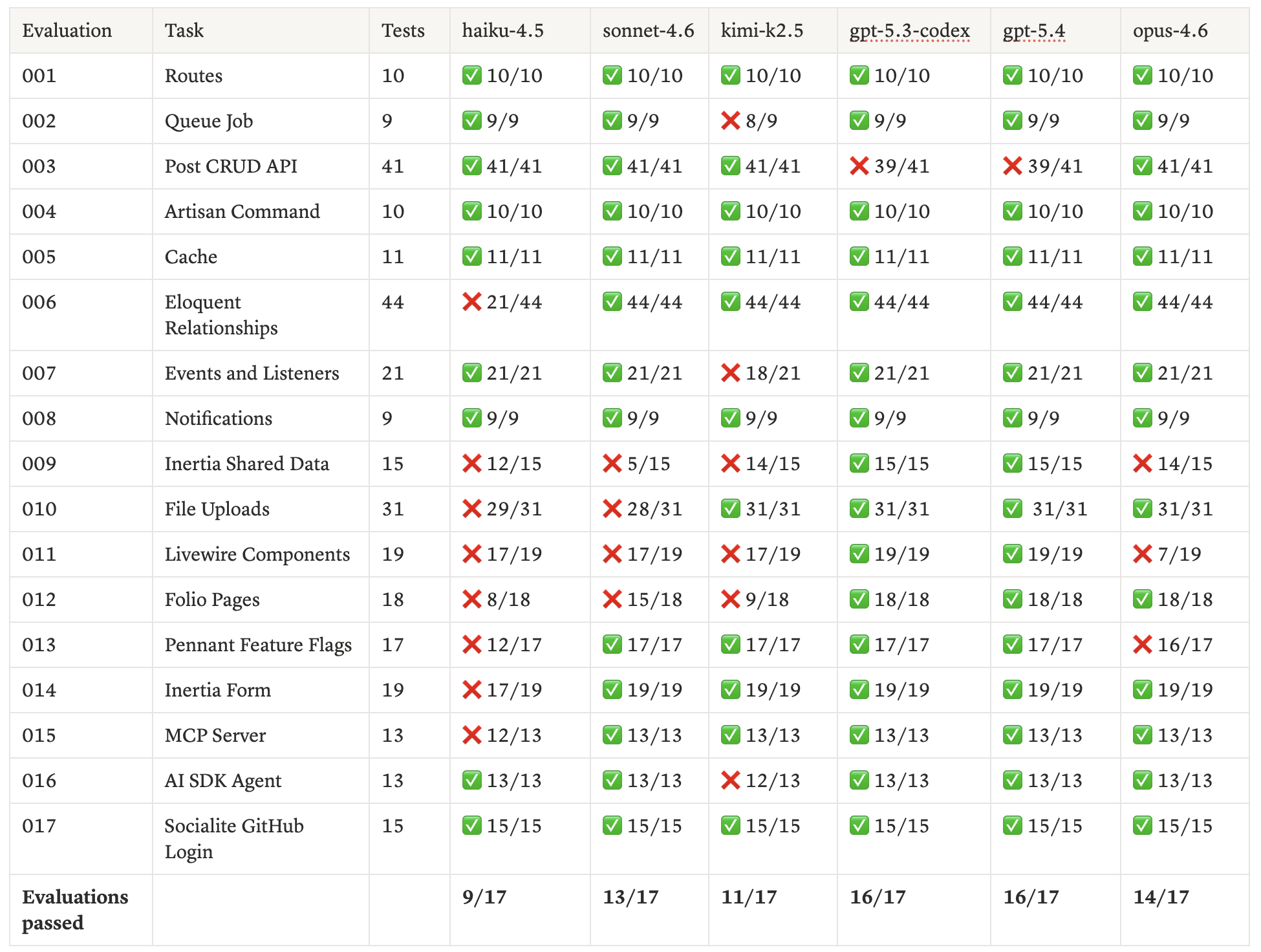
With Boost
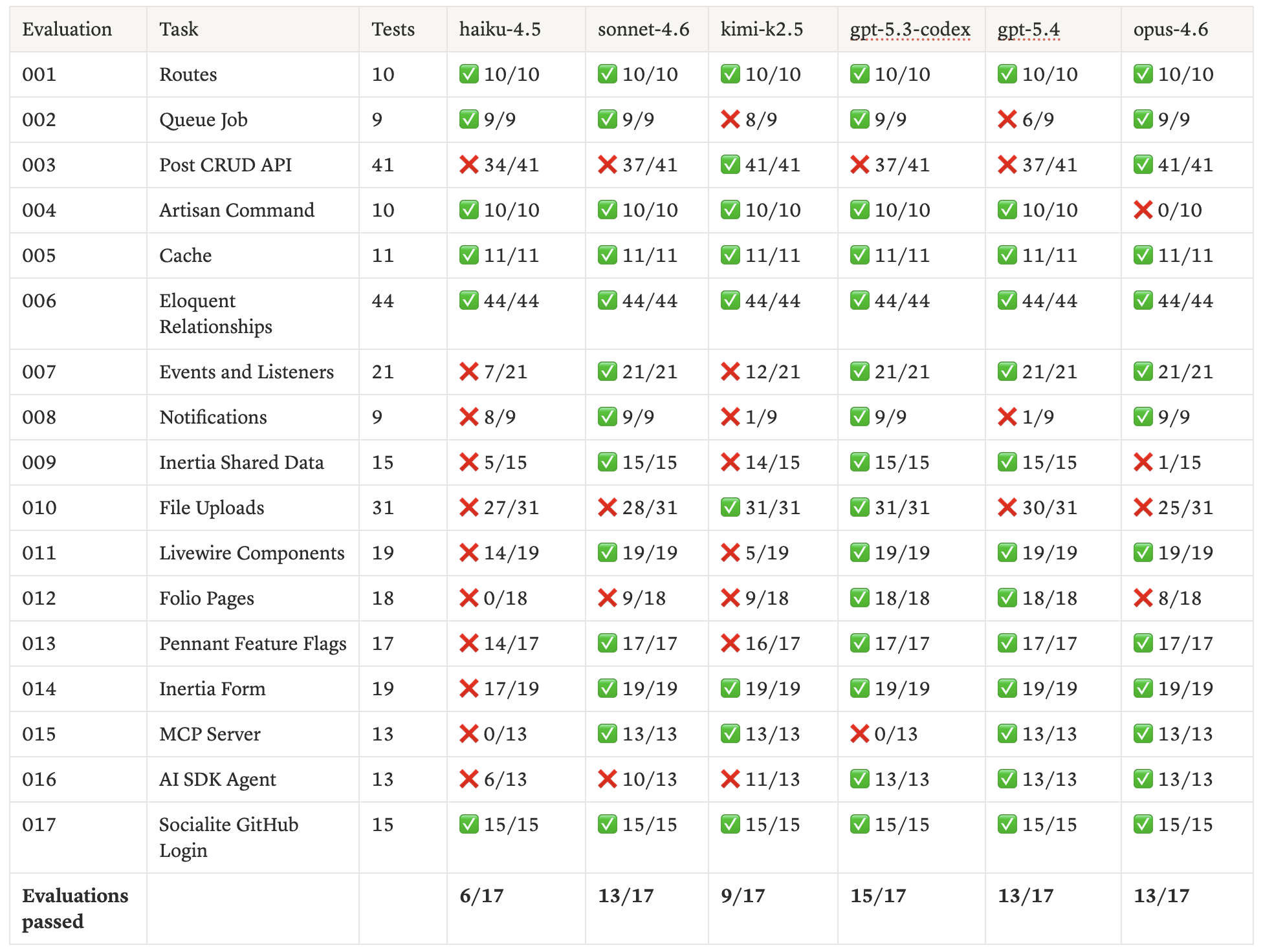
Without Boost
Side-by-Side Summary
| Model | Tests Passed (Boost) | Tests Passed (No Boost) | Delta | Test Accuracy (Boost) | Avg Time (Boost) | Avg Time (No Boost) |
|---|---|---|---|---|---|---|
| haiku-4.5 | 267/315 | 231/315 | +36 | 84.8% | 145s | 164s |
| sonnet-4.6 | 297/315 | 296/315 | +1 | 94.3% | 179s | 208s |
| kimi-k2.5 | 298/315 | 270/315 | +28 | 94.6% | 108s | 122s |
| gpt-5.3-codex | 313/315 | 298/315 | +15 | 99.4% | 191s | 175s |
| gpt-5.4 | 313/315 | 299/315 | +13 | 99.4% | 210s | 202s |
| opus-4.6 | 301/315 | 275/315 | +26 | 95.6% | 217s | 275s |
Does Boost Improve AI Coding Agents?
The short answer is yes. Boost helps every model we tested.
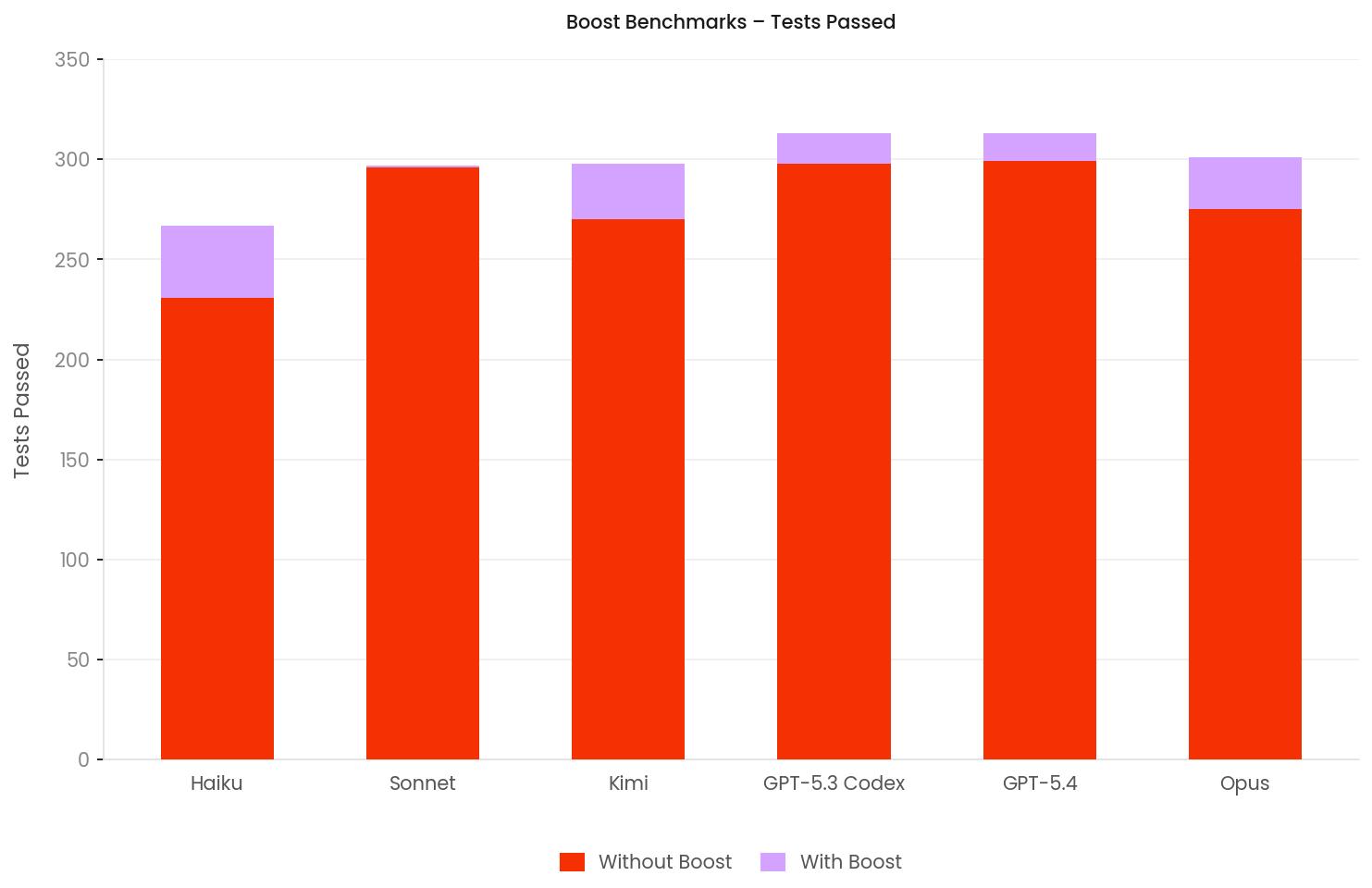 When we started running the benchmarks, the goal was not to prove that Laravel Boost worked. The goal was simply to observe what happened when it was turned on and off. The results turned out to be surprisingly clear. Across the entire benchmark suite, every model either improved or stayed roughly the same once Boost was enabled.
When we started running the benchmarks, the goal was not to prove that Laravel Boost worked. The goal was simply to observe what happened when it was turned on and off. The results turned out to be surprisingly clear. Across the entire benchmark suite, every model either improved or stayed roughly the same once Boost was enabled.
- haiku 4.5
- One of the biggest improvements in the entire benchmark.
- Without Laravel Boost, it struggled heavily on complex evaluations.
- With Boost enabled, the model recovered on several of these harder tasks and improved from 6/17 to 9/17 overall evaluations.
- gpt 5.3 codex
- Already a strong performer even without Laravel Boost.
- Without Boost it passed 15/17 evaluation
- With Boost it improved to 16/17, the highest score in the benchmark run.
- The improvements appeared on more complex Laravel tasks such as Inertia shared data, file uploads, Livewire integrations, and Folio routing.
- gpt 5.4
- The most consistent performer across the entire suite.
- With Laravel Boost enabled, it also reached 16/17 evaluations passed.
- Its single failure was not due to logic errors. Each time it came down to a small configuration detail that prevented a full pass.
- kimi k2.5
- The fastest model in the benchmark suite.
- Averages 108 seconds per evaluation with Boost enabled.
- Maintains 94.6% test accuracy while being significantly faster than the others.
- Overall it provides the best balance of speed and correctness among the tested models.
- sonnet 4.6
- Already very strong even without Laravel Boost.
- Without Boost, it passed 296/315 tests.
- With Boost, it reached 297/315, a small improvement of +1 test.
- The interesting part is performance. With Boost enabled the average runtime dropped from 208s to 179s, meaning the model became noticeably faster while maintaining the same level of correctness.
Taken together, the results tell a simple story. Laravel Boost consistently improves performance on real Laravel tasks, and in several cases, it pushes already strong models over the final line needed to fully pass the evaluations.
What We Learned
Boost helps most on complex tasks
For simple tasks such as adding a route, dispatching a queue job, or writing a cache layer, agents usually already know the patterns. Boost adds MCP calls and extra tokens but rarely changes the outcome.
The real value shows on harder problems where developers would normally reach for documentation. Examples include building custom MCP servers, working with Laravel AI SDK agent loops, configuring Pennant feature flags, or wiring Inertia shared data. In these situations, Boost provides the missing context that helps agents complete the task correctly.
LLM behavior is non-deterministic
We observed noticeable variance when rerunning some evaluations. For example, haiku 4.5 improved from 7/19 to 17/19 on the Livewire evaluation with Boost just by running the same evaluation again. gpt-5.3 codex also flipped from fail to pass on four evaluations in a single rerun even though the model, prompt, and setup were identical.
Because of this, a single run cannot always be treated as definitive. One approach we are considering is running each evaluation multiple times and taking the majority result. For now the results should be treated as directional signals rather than fixed measurements.
Small configuration mistakes can fail the entire evaluation
One common failure pattern was configuration errors. A misconfigured service provider, incorrect binding, or broken migration can stop the Laravel application from booting. When that happens, every test fails even if the core logic is correct.
For example, haiku 4.5 scored 0/13 on the MCP Server evaluation without Boost, likely due to the server being wired incorrectly. The application never started, so no tests could run. This highlights a real risk in AI-assisted Laravel development. Code may look correct, but a small setup issue can silently break the entire application.
Boost introduces some overhead
We also observed that enabling Boost can add token, context, and sometimes time overhead. Since agents make MCP calls to retrieve documentation and framework context, total token usage naturally increases.
This creates a trade-off between maximum correctness and minimal token usage.
In practice, the cost difference is very small. Across our runs, the average delta was roughly $0.05 to $0.20 per evaluation, which is at the API layer and almost negligible at the subscription level.
Still, reducing overhead is an important focus for us. Many recent improvements in Boost have focused on reducing unnecessary context, removing redundant guidelines, and tightening tool outputs so agents get the information they need without inflating the prompt.
The goal is to keep the performance benefits of Laravel Boost while minimizing context and token overhead as much as possible.
What’s Next
We are expanding Boost Benchmarks in several directions:
-
More Evaluations
The suite is growing to cover additional Laravel patterns and edge cases.
-
Adding More Evaluation Parameters
Currently, we only evaluate correctness based on the Pest tests and the architecture test. Going forward, we need to add expectations around agent behavior as well. For example, did the agent call any specific tools or invoke any skills?
-
More Models
So far, we have run gpt-5.4, opus-4.6, sonnet-4.6, gpt-5.3 codex, haiku 4.5, and kimi-k2.5 across the full benchmark suite. As new models ship, we run them against the same evaluations to track progress over time.
-
Web UI
A dashboard for comparing runs, drilling into failures, and exploring results interactively.
In the meantime, if you want to start building Laravel apps faster and more efficiently with the help of AI models, try Laravel Boost. Check our results, and pick the AI agent that best suits your needs.